代码->PRD阅读器的Agent小试牛刀
这篇文章基于 code-as-prd-agent 项目,总结一条很实用的思路:把真实代码仓库挂到本地工作区,交给大模型在“可调用工具”的约束下去读代码、回答问题,从而把“代码事实”转化成可阅读、可追问、可复用的“PRD级解释”。
它不是在替代研发或产品,而是在减少重复沟通成本,让“我先问 agent,再找人确认边界”成为新的协作默认流程。
这里先交代一个我自己踩坑后的结论:我最开始并不是直接上 Claude Code SDK,而是先接了 MiniMax,再手工暴露 bash 和 python 工具,想自己拼一个“能读代码的 Agent”。这条路理论上可行,但在真实仓库问答里效果并不稳定。后来切到 Claude Code SDK 后,体验明显提升。原因不只是“模型更强”,更关键的是:Claude Code SDK 暴露出来的并不是一个普通模型 API,而是一套已经为代码任务打磨过的 agent runtime。
0. 参考地址与实现效果
0.1 项目参考地址
- GitHub 仓库:https://github.com/weijunlei/code-as-prd-agent
- README(含使用说明与界面示意):https://github.com/weijunlei/code-as-prd-agent/blob/main/README.md
0.2 实现效果(README 中的示意)
该项目 README 里给出了三类典型效果图,对应完整链路:
- 仓库初始化任务页:调用
POST /code-as-prd-agent/repo/init后,轮询任务状态,看到running过程与结果 JSON; - 首次问答页:在已挂载工作区上提问,可看到思考过程、工具调用与最终 Markdown 回答;
- 续聊问答页:同一工作区继续追问(文件级细节),服务端基于
chat_id拼接历史对话继续分析。
可直接在 README 对应“实现效果(界面截图)”章节查看。
按典型用户路径,三张效果图建议这样看:
1)仓库初始化任务页(先准备上下文)
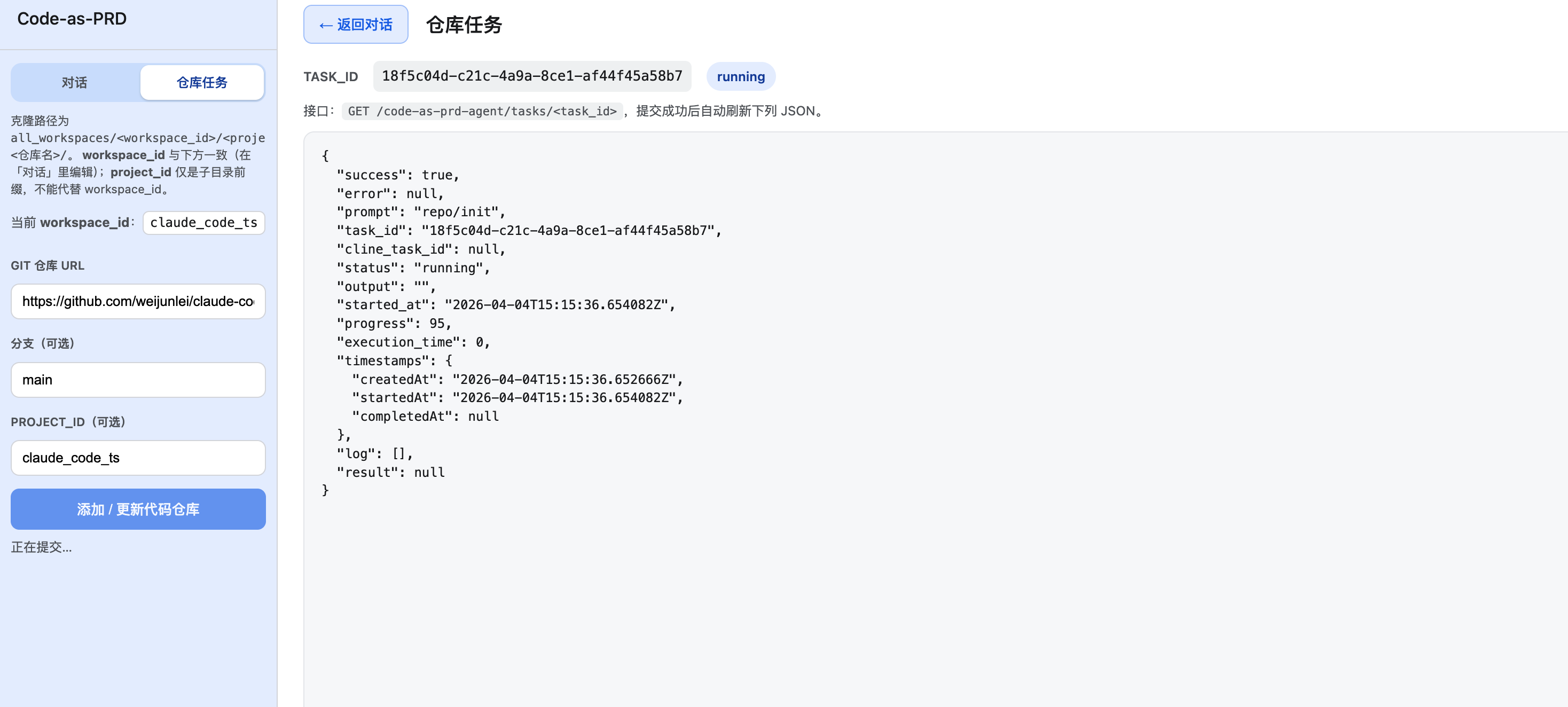
图1:仓库初始化任务页。通过
repo/init创建任务并轮询状态,确认工作区代码已准备完成。
2)首次问答页(开始基于代码问答)
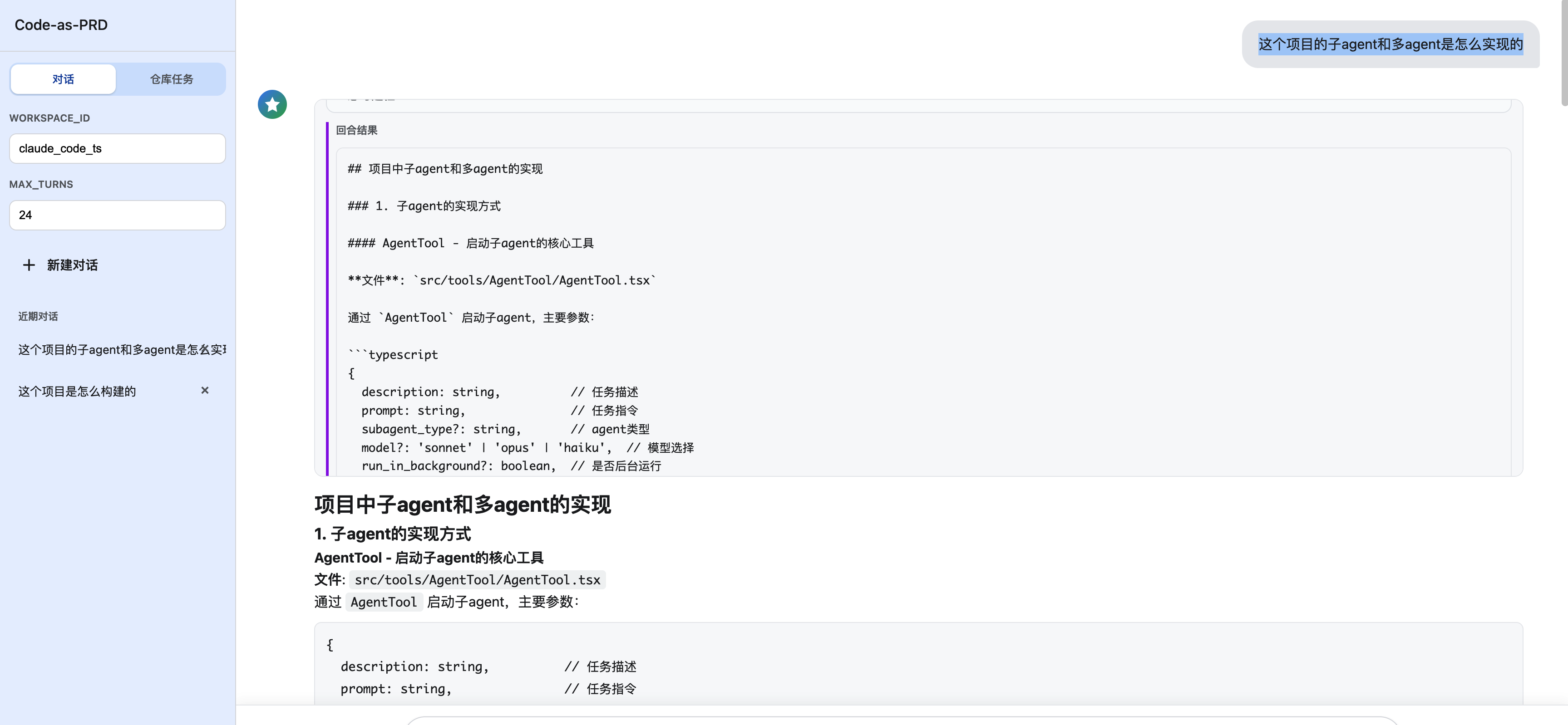
图2:首次问答页。展示模型思考、工具调用过程与最终回答内容。
3)续聊问答页(追问文件级细节)
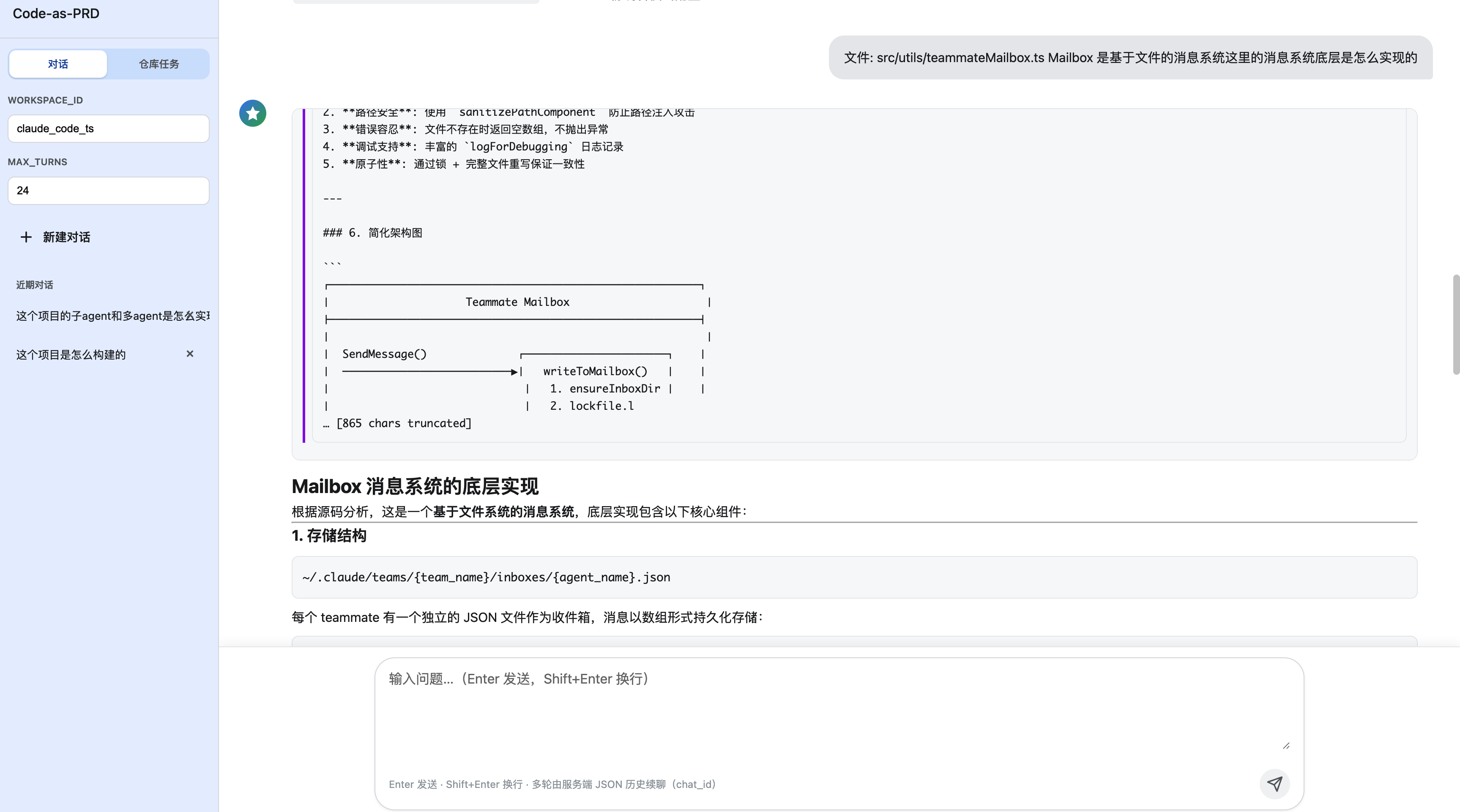
图3:续聊问答页。基于同一
chat_id的历史上下文继续追问,实现文件级深入分析。
0.3 我一开始为什么没有直接用 Claude Code SDK
第一版其实走的是更“朴素”的路线:直接接 MiniMax,给模型两个主要工具:
bash:负责列目录、rg搜索、看文件内容;python:负责临时文本处理、结构化整理、代码片段提取。
它并不是完全不能用,但一进入真实代码库问答,问题就暴露了:
- 工具是有了,但“先做什么、后做什么”几乎全靠 prompt 撑着。
- 模型经常会大范围探索,读很多无关文件,回答看起来很长,但证据链不够聚焦。
- cwd 约束、只读权限、事件流、续聊、工具失败重试,这些工程胶水都得自己补。
- 前端能看到的往往只是 token 流,而不是带语义的
thinking/tool_use/tool_result过程。
我自己的感受是:
“给模型工具”只解决了“它能不能动手”,并没有解决“它会不会像一个读代码很熟练的工程师那样动手”。
把这两条路放在一起看,差异会更直观:
| 维度 | MiniMax + 自建 bash/python 工具 | Claude Code SDK |
|---|---|---|
| 能力边界 | 理论上能列目录、搜代码、读文件 | 同样能做这些事 |
| 工具编排 | 主要靠 prompt 和自己写循环 | runtime 已经内建多轮工具回路 |
| 代码任务偏置 | 需要自己慢慢调 | 天然更偏“先定位、再读代码、再归纳” |
| 事件流 | 多半只有文本/token | 有 thinking/tool_use/tool_result/result 语义事件 |
| 会话管理 | 自己维护历史和续聊 | 已有 sessionId / resume / continueConversation |
| 工程工作量 | 胶水层很多 | 可以把精力更多放在产品约束上 |
所以本文后面想讲清楚的一个重点就是:
为什么同样是“模型 + 工具”,直接接 Claude Code SDK 的效果通常会明显更好。
1. 先回答:什么是 Agent?
1.1 一个工程化定义
在工程语境里,Agent = 普通应用 + 大模型 + 工具调用 + 执行循环。
拆成四层看更清晰:
- 普通应用层:有 API、任务队列、鉴权、日志、状态管理(本项目就是 FastAPI 服务)。
- 模型推理层:理解意图、拆问题、决定下一步(由 Claude 模型承担)。
- 工具层:给模型“手和眼”,比如列目录、读文件、调用检索、访问 API。
- 循环控制层:模型-工具-模型多轮往复,直到得到可交付答案。
所以 Agent 不是魔法,不是“一个超大 prompt”。它本质是把传统软件系统的能力边界,和大模型的语义推理能力,做了一个闭环耦合。
1.2 从数字化到智能化(我的观点 + 主流观点融合)
我认可一个很直观的演进逻辑:
- 数字化阶段:核心价值是“信息留痕、信息透明、信息传播”,把线下流程搬到线上系统。
- 智能化阶段:核心价值是“让系统开始帮人干活”,不仅展示信息,还能主动理解、检索、归纳、执行部分流程。
主流行业里常见提法是:
- Copilot:辅助人完成任务;
- Agent:在边界内可半自主执行任务;
- Human-in-the-loop:关键决策仍由人兜底。
这和“帮助人民干活”的说法并不冲突。更准确地说:Agent 负责高频、标准化、可验证的脑力劳动;人负责价值判断、取舍和责任承担。
2. 传统 RPC/HTTP 与 Stream 交互:差异与巧妙点
2.1 电商/外卖后端常见调用范式
在电商、外卖后端里,我们最熟悉的是:
- 同步 RPC/HTTP:请求一次,返回一个完整结果(库存查询、价格计算、地址校验)。
- 异步任务 + 轮询:先返回 task_id,再查状态(导出报表、批量派单、离线对账)。
这套范式非常成熟,适合“输入结构化、处理过程确定、结果格式固定”的场景。
2.2 Agent 场景为什么偏向 Stream
Agent 问答的过程天然不确定:
- 模型可能先思考,再列目录,再读多个文件,再整合结论;
- 单次耗时和 token 消耗不稳定;
- 用户往往不只关心“最后答案”,还关心“你是怎么得出这个答案的”。
因此 code-as-prd-agent 同时支持了两类接口:
- 非流式:一次性 JSON,适合程序调用;
- SSE 流式:持续输出
delta/done,把思考和工具调用片段实时推送给前端。
2.3 这个 Stream 设计巧妙在哪里
我认为这个项目有三个设计点非常实用:
- 保留传统任务模型:仍有
task_id、状态机、队列并发控制,便于运维和观测。 - 把模型内部过程事件化:
thinking/tool_use/tool_result/text统一映射为前端可消费事件。 - 双轨并存:既能走“传统后端可集成”的 JSON,也能走“人机交互友好”的流式。
这其实是把“互联网后端稳定性范式”和“大模型交互范式”做了融合,而不是替换。
3. 这个项目的实现方法(整体方案)
3.1 一句话架构
FastAPI 负责调度,RepositoryManager 准备代码工作区,ClaudeCodeBridge 通过官方 Python SDK 拉起 Claude Code,在指定 cwd 内读代码并输出流式结果。
3.1.1 README 中的架构图(Mermaid)
flowchart TB
subgraph Client
WEB[Web UI]
API_CLIENT[API Client]
end
subgraph Server
FAST[FastAPI]
REPO[RepositoryManager]
ASK[Ask API]
CHAT[Chat API]
STORE[ConversationStore]
TASK[TaskQueue]
BRIDGE[ClaudeBridge]
end
subgraph Runtime
CLI[Claude Code CLI]
WS[Workspace]
end
subgraph Cloud
LLM[Model API]
end
WEB --> FAST
API_CLIENT --> FAST
FAST --> ASK
FAST --> CHAT
FAST --> REPO
ASK --> STORE
ASK --> TASK
ASK --> BRIDGE
CHAT --> TASK
CHAT --> BRIDGE
REPO --> TASK
BRIDGE --> CLI
CLI --> WS
CLI --> LLM
图4:系统组件关系图。客户端请求进入 FastAPI,由任务与桥接层调度 Claude Code CLI,在工作区内完成代码检索与问答。
3.1.2 README 中的流式问答时序图(Mermaid)
sequenceDiagram participant U as User participant S as FastAPI participant Q as TaskQueue participant C as Claude Code CLI participant W as Workspace U->>S: POST ask S->>S: build prompt with history S->>Q: acquire slot S->>C: run query C->>W: read code files C-->>S: stream deltas S-->>U: text/event-stream S->>Q: release slot
图5:流式问答时序图。请求进入后分配并发槽位,模型边检索边输出 SSE,结束后释放资源。
3.2 核心流程
- 调用
/repo/init:把仓库 clone/pull 到WORKSPACE_BASE_DIR/workspace_id下; - 调用
/ask或/chat:携带workspace_id + question; - 服务端构造 prompt(含规则:必须基于事实、只读、不改文件);
- SDK 以该 workspace 作为
cwd发起 query; - 模型在工具调用中完成“列目录->读文件->归纳回答”;
- 返回 JSON 或 SSE 流;多轮会话可落盘 JSON(
chat_id模式)。
3.3 关键工程点
- 工作区隔离:按
workspace_id管理代码上下文,避免串仓。 - 多轮持久化:把历史落到
.code-as-prd-agent/chat_sessions,下一轮拼进 prompt。 - 并发与队列:避免多个重任务互相挤压。
- 只读约束:通过 disallowed tools 控制“问答不落盘修改”。
4. 为什么“只要 git clone + 全部交给模型”就能 work?
很多人第一反应是:这不就是“把目录丢给 LLM”吗,真的靠谱吗?
我的结论是:在“问题边界清晰 + 工具可用 + 约束明确”的条件下,它确实能稳定 work。
4.1 本质不是“全塞上下文”,而是“按需检索式阅读”
模型并不是一次性把全仓库吃进上下文。真实过程更像:
- 先根据问题形成检索计划(可能涉及哪些模块);
- 用工具列目录定位候选文件;
- 逐步读取关键文件;
- 在多段证据间建立关联;
- 输出带路径依据的解释。
这和人类资深工程师“看陌生项目”的策略非常接近:先扫结构,再看入口,再查链路。
4.2 项目代码里是怎么让它“更稳”的
code-as-prd-agent 做了几件关键事情来提升成功率:
- 强制 cwd 正确:要求模型在 workspace 根目录按相对路径找代码,避免幻觉路径;
- 明确行为规则:必须基于事实、中文回答、只回答问题、不改文件;
- 历史拼接模式:使用
chat_id时,每轮独立会话但拼接完整历史,规避 CLI session 并发问题; - 会话锁与重试:针对 “session already in use” 做互斥和退避,降低续聊失败概率。
4.3 什么时候不 work
也要诚实面对边界:
- 仓库超大且索引成本高时,响应会慢;
- 问题描述过于抽象,模型检索范围会漂;
- 跨仓依赖复杂但未完整挂载时,结论会不全;
- 需要组织级业务背景的判断,不可能仅靠代码得出。
所以工程上正确姿势是:把 Agent 当“高质量一线分析员”,不是“最终拍板人”。
5. 为什么 Claude Code SDK 效果更好?
5.1 先说结论:提升不只是“换了一个模型”
如果只从接口形态上看,MiniMax + 自建 bash/python 工具 和 Claude Code SDK 好像都在做同一件事:
- 给模型一个问题;
- 允许它调用工具;
- 再把结果返回给前端。
但实际效果差异很大。
核心原因是:前者更多是在自己搭一个 Agent,后者是在复用一个已经为代码任务验证过的 Agent runtime。
换句话说,差异不只是 model endpoint,不只是“换成 Claude 所以更聪明”,而是下面几层一起换了:
- 工具调用主循环;
- 代码任务的默认行为偏置;
- 会话和续聊机制;
- 语义化事件流;
- 权限约束与工程稳定性。
5.2 它不是“直接 HTTP 调 Anthropic Messages API”
这个项目通过 claude-agent-sdk 调用 Claude Code 能力,核心调用形态是 query(prompt, options)。options 里会带:
cwdmaxTurnsallowedTools/disallowedToolssessionId/resume/continueConversationmcpServers(可选)
也就是说,它不是简单“传 prompt 等答案”,而是“启动一个带工具执行能力的模型回路”。
很多人容易低估这一点,觉得“我自己接一个兼容接口,再给模型加两个工具,不就差不多了吗”。
但工程上差得其实很远。因为真正难的不是“把工具函数注册出去”,而是让模型在真实代码任务里,稳定走出一条合理的执行链路。
5.3 为什么自建 bash/python 工具效果不如 Claude Code SDK
我自己的第一版里,最直观的问题不是“模型完全不会用工具”,而是工具调用不够像一个熟练工程师的工作方式。
典型表现有这些:
会用工具,但不会稳定地先定位入口再顺链路深挖。
有时候它会先读很多无关文件,再回过头补关键入口,回答虽然长,但结构不紧。容易把
python当成万能胶。
一旦给了python,模型很容易想“一把梭”处理大段文本,而不是老老实实先搜路径、看入口、逐步查证。Prompt 负担特别重。
你得不断告诉它“先rg、再看目录、再读关键文件、不要泛泛总结、一定给证据来源”。
本质上是在用 prompt 手工补 runtime。续聊和稳定性成本高。
多轮历史怎么拼、工具失败怎么重试、会话如何隔离、cwd 如何保证正确,这些都要自己兜。
这并不意味着 MiniMax 这条路一定不行。
更准确地说,是我那版“MiniMax + 自建工具”的实现,还没有把一个成熟的 code agent runtime 真正搭起来。
5.4 Claude Code SDK 实际上替你补了哪几层
在这个任务里,Claude Code SDK 真正有价值的地方,是它把“代码问答 Agent”最难补齐的几层默认给你了。
5.4.1 它给的是成熟的工具回路,不只是工具列表
Claude Code 的执行方式,本质上是一个非常稳定的:
assistant -> tool_use -> tool_result -> next turn
这意味着:
- 模型不是“有空再用工具”;
- 而是在一个被 runtime 明确支持的多轮循环里持续规划、执行、再推理。
这点听起来抽象,但工程上非常重要。
自建版本常见的问题是:工具可以调,但整个调用链没有被打磨成“默认工作流”;Claude Code SDK 则是从底层就假设“代码任务本来就应该多轮查证”。
5.4.2 它天然更像一个“会看代码”的执行器
对代码类问题来说,真正难的不是把文件内容读出来,而是形成一种靠谱的阅读策略:
- 先判断应该去哪几个模块找;
- 再定位入口;
- 再顺调用链找关键事实;
- 最后用自然语言组织解释。
我自己体感里,Claude Code SDK 背后的这套 runtime 和默认提示,更接近一个已经习惯使用终端、搜索、读文件的工程师;
而自建版本更像是“我给模型发了两把扳手,再希望它自己学会怎么修机器”。
5.4.3 它把很多“隐性工程活”也一起带上了
除了模型本身,Claude Code SDK 还顺手帮你补了不少容易被忽略的工程能力:
cwd感知:把模型稳定锁在正确工作区;allowedTools / disallowedTools:更容易做只读约束;maxTurns:避免无限探索;sessionId / resume / continueConversation:支持原生续聊;- 事件语义统一:便于前后端把 Agent 过程完整展示出来。
这些能力单看都不复杂,但如果你全部自己实现,工程胶水会非常多,而且容易在边界条件上漏坑。
5.5 为什么它能做出“流式可观测”
SDK 会持续返回消息事件,常见类型有:
systemassistant(含thinking、tool_use、tool_result、text块)result
服务端再把这些 wire 消息转换成 SSE 事件推给前端,因此你可以看到一个“正在思考和查代码”的过程,而不是黑盒等待。
这也是我从自建版本切过来后非常明显的感受:
前端不再只是“看到模型在吐字”,而是能看到 Agent 在真实执行。
5.6 续聊策略为什么分两种
这个项目里我认为很务实的一点是:它并不执着于单一路径。
- CLI session 续聊:沿用模型原生会话,但有并发占用风险。
- JSON 历史续聊(推荐):每轮新会话 + 历史拼 prompt,工程可控性更高。
这背后是个典型的工程取舍:
理论连续性(原生 session) vs 运行稳定性(服务端可控历史)。
6. 和“传统代码搜索/文档系统”相比,价值在哪
如果只有搜索,你拿到的是“片段”;
如果只有文档,你拿到的是“可能过时的解释”;
如果只有人肉答疑,你拿到的是“口头记忆”。
而代码->PRD阅读器 Agent 的价值是三者组合:
- 以代码为事实来源;
- 以自然语言组织解释;
- 以流式交互支持追问与澄清。
它把“查证事实”和“生成可读说明”放到同一链路中,显著缩短了产品、研发、测试之间的认知对齐时间。
7. 落地建议(给团队)
- 先从只读问答开始,别一开始就自动改代码。
- 问题模板化:沉淀“是否已实现/入口在哪/边界条件/异常链路”这类固定问法。
- 会话持久化:重要讨论的
chat_id结果可二次沉淀为 PRD 附件或技术说明。 - 明确责任边界:Agent 给的是证据化建议,最终决策必须人来签字。
8. 总结
“代码->PRD阅读器”这类 Agent 项目之所以有现实价值,不在于它做了多复杂的算法,而在于它把一个高频痛点工程化了。
而这件事能成立,一个很关键的原因并不是“换了一个模型名字”,而是选对了 runtime:
从我自己的实践看,MiniMax + 自建工具 和 Claude Code SDK 的差异,核心不只是模型能力,而是后者已经把代码任务的工具回路、会话机制、事件流和行为约束打磨成了成体系的执行器。
落到结果上,它带来的价值是:
- 用代码事实替代记忆沟通;
- 用流式交互替代黑盒等待;
- 用可复用会话替代一次性口头解释。
从数字化到智能化的关键一步,正是让系统开始承担“理解 + 检索 + 归纳”的劳动。
这个项目已经把这条路走通了一个非常实用的版本。

