Unicoder: A Universal Language Encoder by Pre-training with Multiple Cross-lingual Tasks
1. 摘要
Unicoder是一个对于不同语言通用的语言编码器。该模型在某个语言的任意NLP任务之后可以直接运用于其他语言。与该方法类似的有Multilingual BERT和XLM,新提出了跨语言的词恢复、释义分类和遮盖语言模型三个预训练任务。这些任务帮助Unicoder学习到了不同语言深层次的内容。同时该方法也发现,在某些任务上进行微调可以让效果得到提升。该模型微调了XNLI和XQA之后,在XLM的基础上,XNLI提升了在15中语言上提升了1.8%,而在XQA上提升了5.5%。
3. 主要贡献
- 提出了3个跨语言预训练任务,更好的获取语言无关编码
- 创建了一个新的跨语言QA数据集XQA
- 验证了微调加上语言预训练可以显著提升模型效果
- 在XNLI上实现了SOTA
4. 模型实现
- 在实现上参照了XLM模型,使用BPE共用词表,下采样数据多的语言预料,避免目标语言的词被分为太多的字符级别。
- 预训练任务
- MLM(masked language model) Multilingual Bert
- TLM(translation language model): XLM
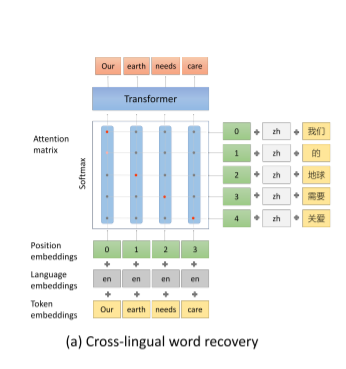
- 跨语言的词语恢复(Cross-lingual Word Recovery): learn the underlying word alignments between two languages 使用注意力矩阵处理后的X作为input还原X
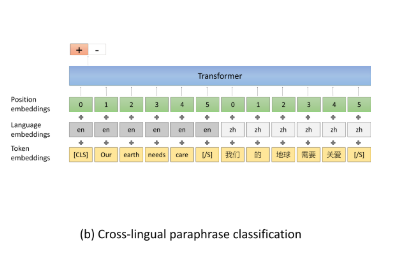
- 跨语言的同义句子分类(Cross-lingual Paraphrase Classification)使用两个不同语言的句子判断两个句子是否是相同的意思,获取两个语言句子层面的对应关系。同时在采样负例时采用两段式的采样方法,首先使用一个轻量级的随机采样方法获取是否是同一含义,然后利用这个模型寻找最相似但是不相等的负样例。该方法主要是使得训练任务难度变高。
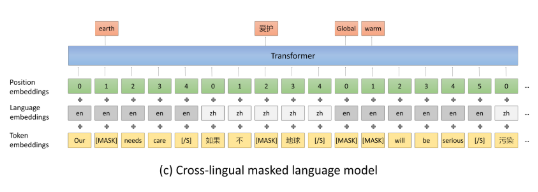
- 在文档级别上MLM,句子是多语言的。因为跨语言的词级别的多语言较少且可能不通顺,所以需要使用句子组成一个连贯的文档
- 跨语言微调(设目标任务是测试中文数据集)
- 测试数据翻译(Translate Test)将中文的测试数据翻译成英文的测试数据,将问题转化成英文训练、英文测试的问题。
- 训练数据翻译(Translate Train)将英文的训练数据翻译成中文的训练数据,将问题转化成中文训练、中文测试的问题
- 跨语言测试(Cross-lingual Test),也就是直接将在英语训练集上训练得到的模型在中文上进行测试。
- 跨语言微调是通过将英语翻译成其他语言,在英语和其他语言上进行训练,然后再中文数据上进行测试
5. 实验细节
- 训练细节
- 模型结构 12层16头1024个隐层的transformer
- 预训练详情 从XLM初始化(节约时间)
- 数据
- XNLI:跨语言推理任务
- XQA:新提出数据XQA,Cross-lingual Question Answering,三语数据集,只有英文有训练数据,判断问题和答案是否相关
6. 实验效果
- XNLI结果:在TRANSLATE-TRAIN的XLM的基础上,多语言微调的整体提升1.8%,其中在使用多语言微调之后提升1.1%,Unicoder相对XLM提升0.7%。所以可以看出Unicoder对多语言的知识掌握能力更强
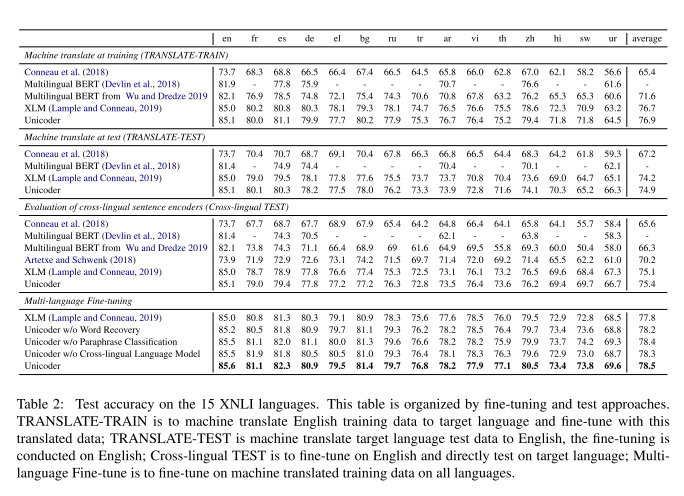
- XQA结果:在TRANSLATE-TRAIN的XLM的基础上,多语言微调的整体提升5.5%,其中在使用多语言微调之后提升3.5%,Unicoder相对XLM提升2%
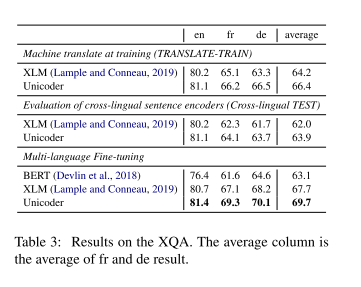
- 总体来说语言越多越好,但是在双语fine-tuning中Vietnamese和Urdu甚至相对单语是有害的
7. 总结及启迪
- 作者提出了三种全新的预训练任务,三个任务对模型效果均有提升
- 提出了一种多语言预训练方案,相对只将原语言翻译效果有提升
- 总体而言,在微调阶段,语言越多效果越好
- 实践了预训练中多任务的作用,同样也实践了预训练任务的难度对结果影响(Cross-lingual Paraphrase Classification)
- 多语言微调是否可以看作是一种数据微调?该模型对于获取翻译之后多语言特征强,所以可以考虑对增强数据的增强捕捉能力?

