Multilingual NMT with a language-independent attention bridge
摘要
作者通过整合跨所有语言共享的中间注意力桥获取到为位机器翻译系统准备的句子表征架构。作者通过在编码端的inner-attention语言特定的编码和解码器连接进行训练。注意力桥利用每种语言的语义进行翻译,并发展成一种语言无关的意义表示,可以有效地用于迁移学习。作者为有效开发多语言神经网络机器翻译提供了一种新的框架。作者在多平行数据上进行了系统性的测试。该模型在双语模型和零样本的翻译上提升较大,展现了该模型的抽象和迁移能力。
主要贡献
- 提出了一种多语言翻译系统,有效解决学习语言无关的句子表征任务
- 验证了模型能够通过共享表征实现有效的迁移学习和零样本翻译。
- 证明了经过多语言训练的词嵌入可以改善大多数下流和展示了从组合翻译任务上获取抽象学习的句子探测任务
模型实现
整体上
- 使用了标准的encoder-decoder加上attention机制
- 加上了self-attention层共享所有的语言对完成语言无关层
具体实现
- 编码器用用BiLSTM得到$n*d_h$句子向量表示,然后使用多层注意力将该表示转换为固定大小的向量$M\in R^{d_h * k}$,k为attention head数量。
$$\begin{aligned}
A &= softmax(W_2ReLU(W_1H^T)) \\
M &= AH
\end{aligned}$$ - 解码器使用通用的带注意力的解码器,该解码器初始向量通过M的平均池化的到。解码器用的是单向的LSTM
- 增加惩罚项避免学习到重复的信息。作者使用的是Frobenius正则化解决
$$L = -log(p(Y|X)) + ||AA^T - I||_F^2$$
结果分析
- 在双语翻译结果上有所下降,作者解释是因为将有10个self-attention组成的固定的句子向量没有包含多语言信息
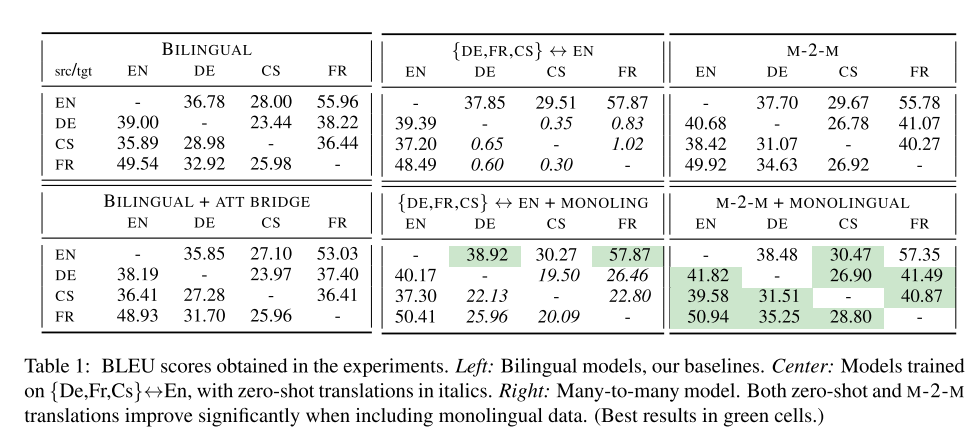
- 在多对一和一对多的实验中,但是多对一就有一定的效果提升,然后在训练过程中加上了单语数据,具体是将语言A的句子直接复制形成句子对,和平行预料一起进行训练。
- 在多对多模型上,在双语模型基础上有了巨大提升,加上单语预料后也有增益。同时在零样本学习上也强于之前的多对一模型。
- 训练得到向量在下流任务上结果:在相同预料库下相对于Glove-BoW有所提升,但是可能相对通用的预训练模型微调的效果可能有点不够看,但是为零样本、少样本的跨语言学习提供一种解决方案
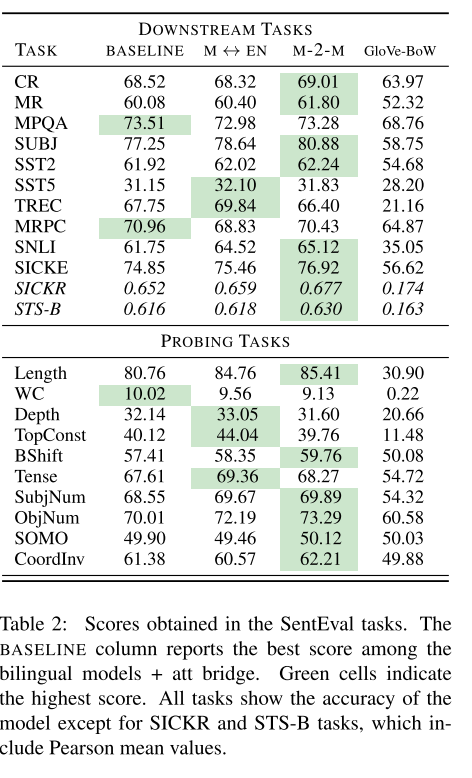
总结
- 对传统的encoder-decoder进行了三项改造:使用了特定语言的encoder-decoder、语言无关的共享attention bridge以及惩罚项。
- 使用Attention Bridge合理地将多语言表征融合。该融合是否可以直接用于预训练任务?
- Multi-Head学习到重复内容是否可以使用其他方法进行一种增加“惩罚项”,因为该方法中的Frobenius其实效果提升较小或者对有些任务有负作用

